Transcribe, translate, or transliterate: An investigation of intermediate representations in spoken language models



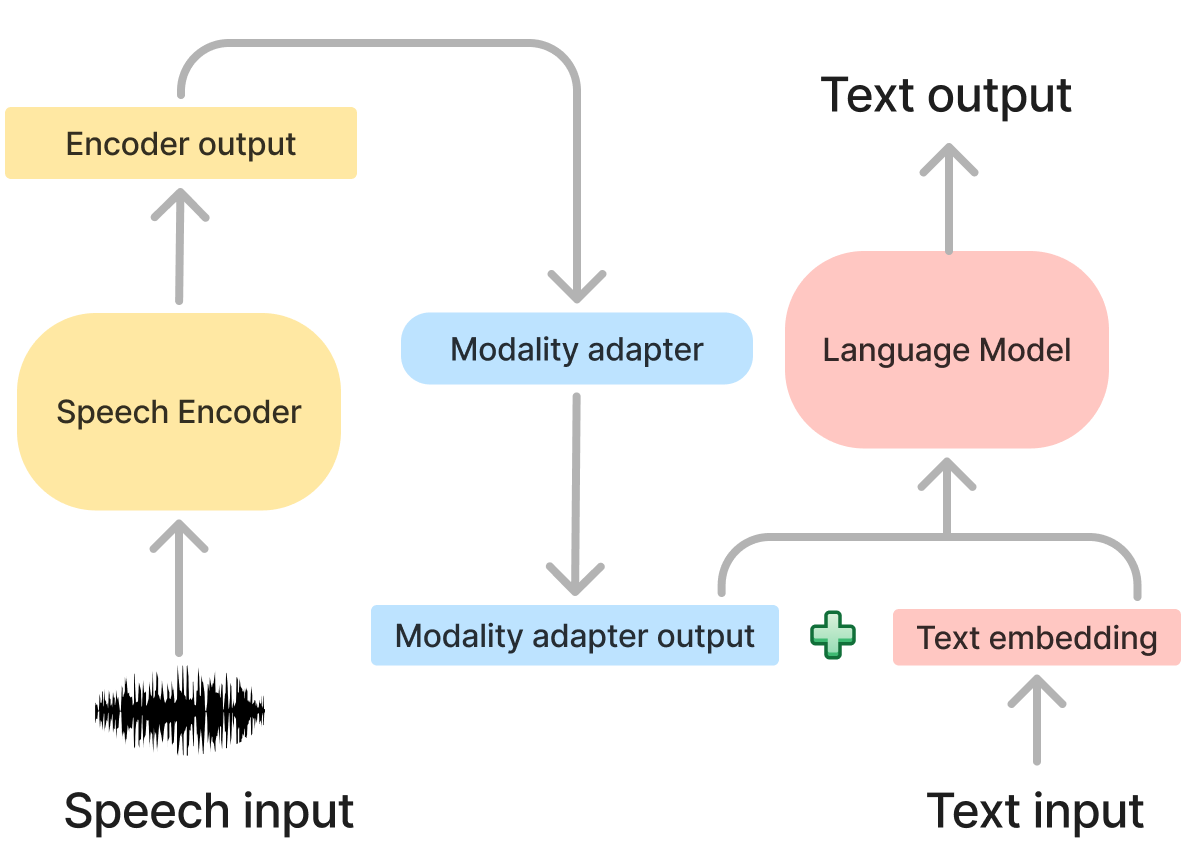
Spoken language models (SLMs) that integrate speech with large language models rely on modality adapters to map the output of speech encoders to a representation that is understandable to the decoder language model. These modality adapters are crucial, yet we know very little about how they transform representations. Here we investigate modality adapters in three SLMs (SALMONN, Qwen2-Audio and Phi-4 Multimodal-Instruct), examining the modality adapter output representations themselves and also how they differ from the speech encoder output.
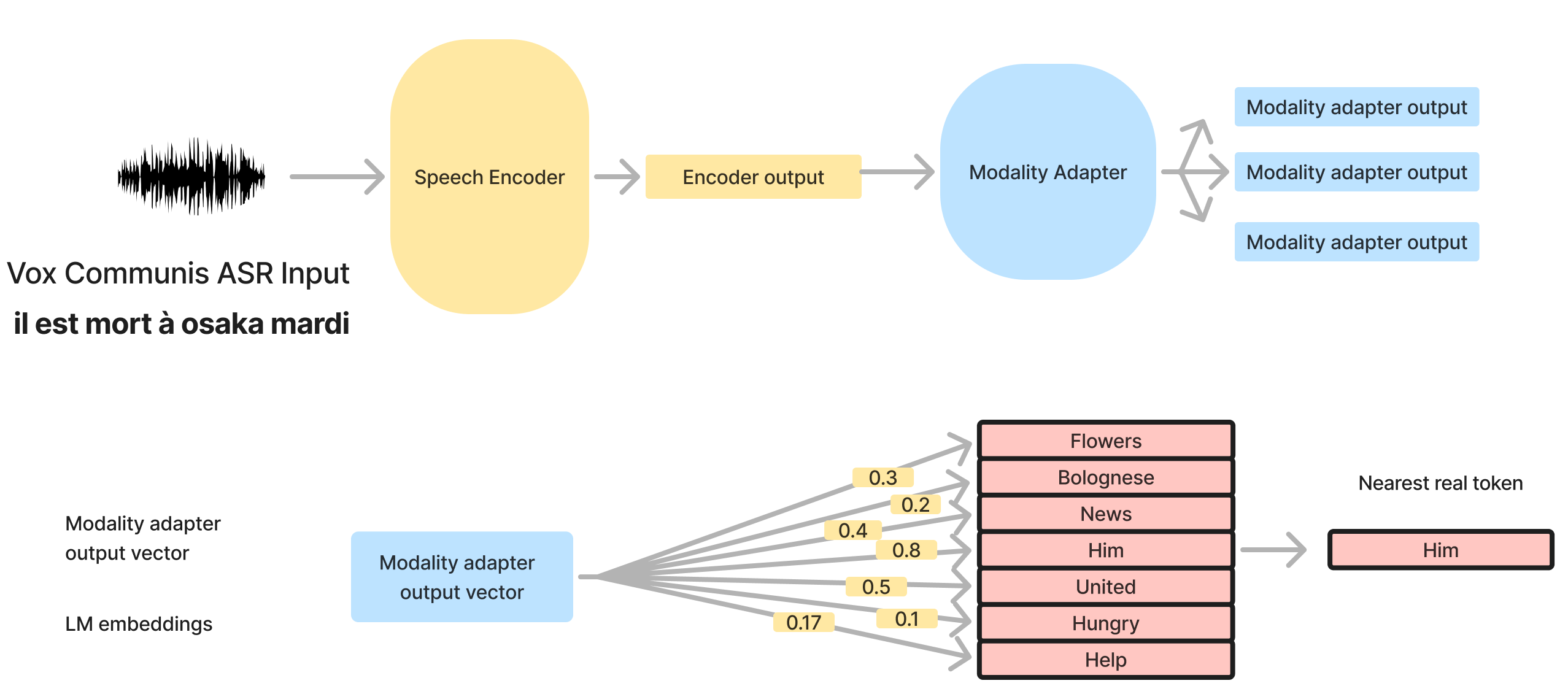
We map modality adapter representations onto decoder language model tokens and find that for mdoels using a Whisper encoder, modality adapters appear to represent the meaning of the input using an English-based interlingua, allowing them to handle languages unseen in instruction tuning. We next look at representational dynamics: how the representation changes from the encoder through the modality adapter module. Our work demonstrates two strategies for modality adapters: producing as their output primarily an English-based semantic representation or primarily an English-based phonetic representation. We hypothesize that which arises depends on whether the speech encoder is trained only for speech recognition or also for speech translation.
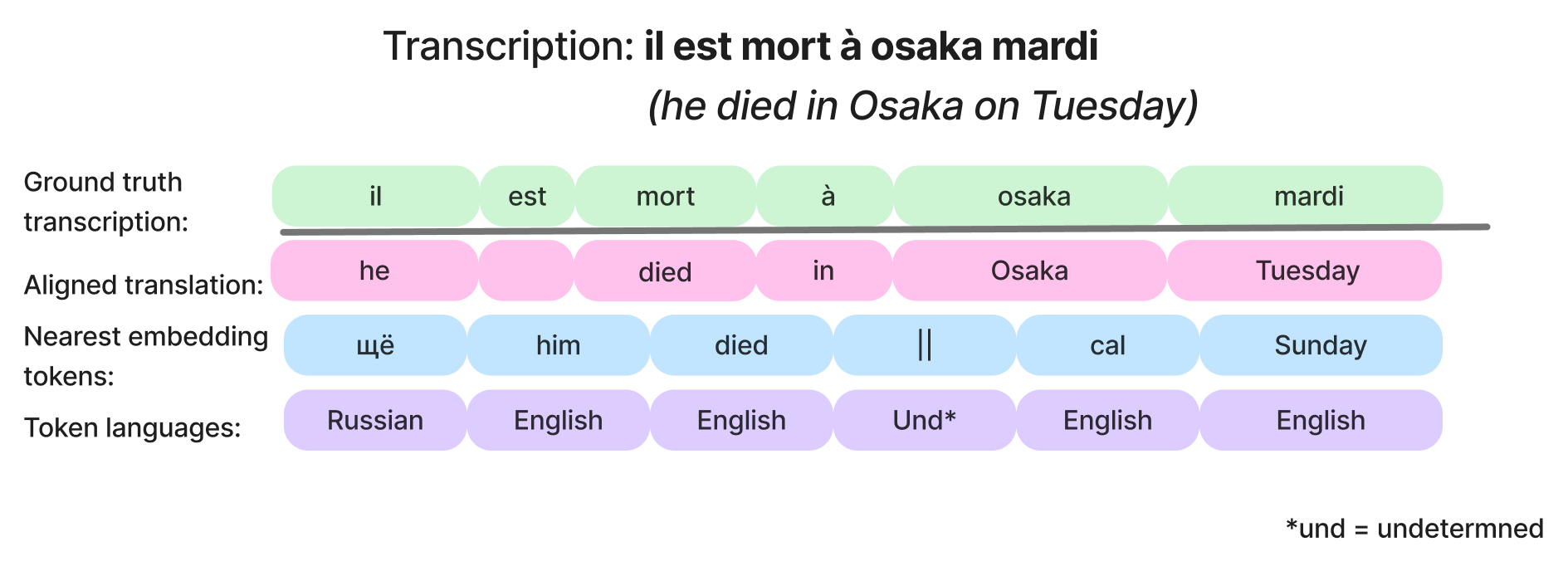
We find that all models have mostly English intermediate representations across languages. For models that are trained with a Whisper encoder, the intermediate representations are mostly an English translation or semantic representation of the speech, likely due to the speech translation training of the Whisper model. Although Phi-4-Multimodal-Instrcut MAs do not seem to represent semantics, the representation of phonetics are still in English.



Tolúlọpẹ́ Ògúnrẹ̀mí is a PhD student at Stanford University in the Stanford NLP Group. Her work focusses on speech and language processing for low-resource languages, currently African languages.